Alamofireでパラメータをenumで扱えるようにする
Alamofireといえば、言わずと知れたSwift界のHTTPクライアント。名前の由来はテキサスの花の名前らしいすね。
今回はAlamofireのリクエストパラメータをenumで扱うという話。
大前提。Stringは脆い!
Stringはすべての表現を兼ね備える万能な型です。
色は"#FFFFFF"という値で扱うこともできるし、URLも"http://blog.matsuokah.jp/"と扱うことができます。
故に、APIレスポンスの型にStringが採用される変数も多いですよね。
(数値とBool以外Stringで受け取ってクライアントでパースするのが一般的なような)
しかしながらStringを型として用いる場合、その変数には「特定の値が入っている」ことを前提として扱わなければならないので、コードの堅牢性を下げうる型とも言えます。
let color: String = "http://blog.matsuokah.jp/"と入力できてしまうが故にエラーはランタイムで発生することでしょう。コンパイラ言語のありがたみもありません。
今回はこれをAlamofireのパラメータに当てはめて考え、キー値をenumで扱えるようにしました
Alamofireのパラメータは [String: Any]という形式
AlamofireではAlamofire.Parametersというエイリアスが[String:Any]に参照しており、
Dictionaryをセットするだけでリクエストに応じて柔軟にパラメータを設定してくれる形式になっています。
dictionaryを代入するポイントはAlamofire.requestのparamters:なので、ラップする箇所や各所のAPIサービス周辺でパラメータを用意する形式がシンプルなやり方可と思います。
APIClientにAPIのエンドポイント、パラメータ、返却する方をジェネリクスで決めてDataStoreやModelからコールするイメージです
struct SearchAPIService { let apiClient: APIClient // APIをコールするServiceのメソッドの一例 func searchUser(userName: String) -> Observable<SearchResult> { var paramter = [String: Any]() parameter["user_name"] = userName return apiClient.get(endpoint: endpoint, parameter: parameter) } }
Parameterをenum化する
import Foundation import Alamofire /// Dictionaryから新たなDictionaryを作る // MARK: - Dictionary extension Dictionary { // MARK: Public Methods public func associate<NKey, NValue>(transformer: @escaping ((Key, Value) -> (NKey, NValue))) -> Dictionary<NKey, NValue> { var dic: [NKey: NValue] = [:] forEach { let pair = transformer($0.key, $0.value) dic[pair.0] = pair.1 } return dic } } // MARK: - ParameterKey public protocol ParameterKey: Hashable { var key: String { get } } // MARK: - RequestParameter public protocol RequestParameter { associatedtype T : ParameterKey // MARK: Internal Properties var parameters: Alamofire.Parameters { get } // MARK: Private Properties var parameter: [Self.T: Any] { get set } // MARK: Internal Methods mutating func setParameter(_ key: Self.T, _ value: Any) } // MARK: - APIParameter public extension RequestParameter { public var parameters: Alamofire.Parameters { if parameter.isEmpty { return [:] } return parameter.associate { (param, any) in return (param.key, any) } } public mutating func setParameter(_ key: Self.T, _ value: Any) { parameter[key] = value } }
// MARK: - SearchParameterKeys public enum SearchParameterKeys: ParameterKey { case userName // MARK: Internal Properties public var key: String { switch self { case .userName: return "user_name" } } } // MARK: - SearchParameter public struct SearchParameter: RequestParameter { public typealias T = SearchParameterKeys public var parameter: [SearchParameterKeys : Any] = [:] }
struct SearchAPIService { let apiClient: APIClient // APIをコールするServiceのメソッドの一例 func searchUser(userName: String) -> Observable<SearchResult> { var paramter = SearchParamter() parameter.set(.userName, userName) return apiClient.get(endpoint: endpoint, parameter: parameter.parameters) } }
こうすることで、SearchAPIに対して設定できるパラメータはSearchParameterのみ。SearchParameterでセットできるキー値はSearchParameterKeysのみとなりました。
また、qというキーに対して今はenum値qを用いてますがqueryのような、デスクリプティブな表現もできるようになります。
Pros & Cons
Pros
- キーに設定できるパラメータが絞られるようになった
- APIServiceのインタフェースにParameterを用いることができるようになったので、引数が少なく、拡張性をもたせることができる
- キーenumはキー文字列へのaliasなのでより、説明的な表現ができる
Cons
- キー値の共通がこのままだとできないので、API毎に似たような定義が増える
まとめ
Consに関してはプロトコルで共通部分を抜き出すなどすればなんとかできそうだと思っています。
また、主観ですがAPIに対して特定のキー値があることのほうが多いので問題に当たるケースは少ないかなと楽観してます。
今回載せたコードは下記のリポジトリに載せてます。(テストは動きません無)
Swiftをせっかく使うならProtocol Oriented Programmingしたい
まえがき
6月からAndroidエンジニアからiOSエンジニアになり、Objective-CをSwift化するプロジェクトをやっている。 iOSはiOS5,6時代に開発した経験はあるがSwiftは0からということで、最近色々記事を読んでいた。Swiftいいですね。僕は好きです。
その中でWWDCのセッションである「Protocol-Oriented Programming in Swift - WWDC 2015 - Videos - Apple Developer」に出会い、
オブジェクト指向な実装をしてしまっていたところを軌道修正中であります。
この記事はオブジェクト指向のアプローチからプロトコル指向のアプローチまで段階を踏んで実装することで、オブジェクト指向との違いやプロトコル指向の理解を深めようというモチベーションで書いた。
また、Playgroundのソースコードは下記のリポジトリにおいてある
プロトコル指向プログラミングとは
- プロトコルに性質を定義し、プロトコルに準拠していくことで処理の共通化をはかっていくアプローチ
- 主にprotocol, struct, enum, extensionで、基本的にはイミュータブルなデータ構造
対比されるもの
オブジェクト指向にとって代わるものとされている。
なぜオブジェクト指向と取って代わるのか
下記に挙げるオブジェクト指向の利点(目的)はSwiftのprotocol, struct , extensionで実現し、さらに欠点である複雑性を排除することが出来るから
オブジェクト指向の利点(引用)
Protocol-Oriented Programming in Swift - WWDC 2015 - Videos - Apple Developerのでは下記を上げている
- Encapsulation(カプセル化)
- Access Control(アクセスコントロール)
- Abstraction(抽象化)
- Namespace(名前空間)
- Expressive Syntax表現力のある構文。例えばメソッドチェーン
- Extensibility(拡張性)
これらは型の特徴であり、オブジェクト指向ではclassによって上記を実現している。
また、classでは継承を用いることで親クラスのメソッドを共有したり、オーバーライドによって振る舞いを変えるということ実現している。
しかし、これらの特徴はstructとenumで実現することが可能。
クラスの問題点
暗黙的オブジェクトの共有
classは参照であるため、プロパティの中身が書き換わると参照しているすべての箇所に影響が及ぶ。即ち、その変更を考慮した実装による複雑性が生まれているということ。
継承関係
Swiftを含め、多くの言語ではスーパークラスを1つしか持てないため、親を慎重に選ぶという作業が発生している。また、継承した後はそのクラスの継承先にも影響が及ぶので後から継承元を変えるという作業が非常に困難になる。
型関係の消失
オブジェクト指向をSwiftで実現しようとすると、ワークアラウンドが必要になる
/// データクラスをキャッシュするクラスをCacheとし、更新のためにmergePropertyというメソッドを用意した class Cache { func key() -> String { fatalError("Please override this function.") } func mergeProperty(other: Cache) { fatalError("Please override this function.") } } class FuelCar: Cache { var fuel: Int = 0 var id: String init(id: String) { self.id = id } override func key() -> String { return String(describing: FuelCar.self) + self.id } override func mergeProperty(other: Cache) { guard let car = other as? FuelCar { return } fuel = car.fuel } } var memoryCache = [String:Cache]()
発生しているワークアラウンド
- 抽象関数を実現するためにスーパークラスで
fatalErrorを使っている - 各クラスの実装でランタイムのキャストを行っている
- もし、FuelCar, BatteryCarで共通処理を実装するCarというスーパークラスを定義したくなったら、CacheFuelCarなどとデータクラスを分けるような実装が必要になる
簡単なキャッシュをオブジェクト指向からプロトコル指向にリファクタしてみる
classを使ってオブジェクト指向な実装
typealias CacheKey = String class Cacheable { func key() -> CacheKey { fatalError("Please override this function") } func merge(other: Cacheable) { fatalError("Please override this function") } } class CacheStore<CacheableValue: Cacheable> { var cache = [CacheKey:CacheableValue]() func save(value: CacheableValue) { if let exist = cache[value.key()] { exist.merge(other: value) cache[value.key()] = exist return } cache[value.key()] = value } func load(cacheable: CacheableValue) -> CacheableValue? { return cache[cacheable.key()] } } class FuelCar: Car { var fuelGallon: Int init(id: String, fuelGallon: Int = 0) { self.fuelGallon = fuelGallon super.init(id: id) } override func key() -> CacheKey { return id } override func merge(other: Cacheable) { guard let fuelCar = other as? FuelCar else { return } self.fuelGallon = fuelCar.fuelGallon } } var fuelCarCache = CacheStore<FuelCar>() var car1 = FuelCar(id: "car1", fuelGallon: 0) fuelCarCache.save(value: car1) print(cacheable: car1, store: fuelCarCache) // print: 0 car1.fuelGallon = 10 print(cacheable: car1, store: fuelCarCache) // print: 10 fuelCarCache.save(value: car1) print(cacheable: car1, store: fuelCarCache) // print: 10
問題点
- CacheableとCarという共通クラスを持つために、CarがCacheableを継承する必要がある
- Carでインスタンスを作ってキャッシュに入れることができてしまう。ラインタイムでエラー
mergeメソッドではfuelCarへのランタイムでのキャストが発生するcar1.fuelGallon = 10を記述した時点で、キャッシュを参照している部分全てに影響が出ている
protocolを使う
//: Playground - noun: a place where people can play import Foundation protocol HasId { var id: String { get } } protocol Mergeable { func merge(other: Self) -> Self } typealias CacheKey = String protocol KeyCreator { func key() -> CacheKey } protocol Cacheable: KeyCreator, Mergeable { } class CacheStore<CacheableValue: Cacheable> { var cache = [CacheKey:CacheableValue]() func save(value: CacheableValue) { if let exist = cache[value.key()] { cache[value.key()] = exist.merge(other: value) return } cache[value.key()] = value } func load(keyCreator: KeyCreator) -> CacheableValue? { return cache[keyCreator.key()] } } class Car: HasId { var id: String init (id: String) { self.id = id } } class FuelCar: Car, Cacheable { var fuelGallon: Int init(id: String, fuelGallon: Int = 0) { self.fuelGallon = fuelGallon super.init(id: id) } func key() -> CacheKey { return id } func merge(other: FuelCar) -> Self { if self.id == other.id { self.fuelGallon = other.fuelGallon } return self } } func print<Key: KeyCreator>(key: Key,store: CacheStore<FuelCar>) { print("fuelGallon: \(store.load(keyCreator: key)!.fuelGallon)") } var fuelCarCache = CacheStore<FuelCar>() var car1 = FuelCar(id: "car1", fuelGallon: 0) fuelCarCache.save(value: car1) print(key: car1, store: fuelCarCache) // print: 0 car1.fuelGallon = 10 print(key: car1, store: fuelCarCache) // print: 10 fuelCarCache.save(value: car1) print(key: car1, store: fuelCarCache) // print: 10
改善されたポイント
mergeでは引数の型がコンパイル時に決まるようになったCarクラスをCacheできないようになった。
structを使う
//: Playground - noun: a place where people can play import Foundation protocol HasId { var id: String { get } } protocol Mergeable { func merge(other: Self) -> Self } typealias CacheKey = String protocol KeyCreator { func key() -> CacheKey } protocol Cacheable: KeyCreator, Mergeable { } struct CacheStore<CacheableValue: Cacheable> { var cache = [CacheKey:CacheableValue]() mutating func save(value: CacheableValue) { if let exist = cache[value.key()] { cache[value.key()] = exist.merge(other: value) return } cache[value.key()] = value } func load(keyCreator: KeyCreator) -> CacheableValue? { return cache[keyCreator.key()] } } protocol Car: HasId { } struct FuelCar: Car, Cacheable { var id: String var fuelGallon: Int func key() -> CacheKey { return id } func merge(other: FuelCar) -> FuelCar { return FuelCar(id: self.id, fuelGallon: other.fuelGallon) } } func print<Key: KeyCreator>(key: Key,store: CacheStore<FuelCar>) { print("fuelGallon: \(store.load(keyCreator: key)!.fuelGallon)") } var fuelCarCache = CacheStore<FuelCar>() var car1 = FuelCar(id: "car1", fuelGallon: 0) fuelCarCache.save(value: car1) print(key: car1, store: fuelCarCache) // print: 0 car1.fuelGallon = 10 print(key: car1, store: fuelCarCache) // print: 0 fuelCarCache.save(value: car1) print(key: car1, store: fuelCarCache) // print: 10
改善されたポイント
- キャッシュを
saveするまで、キャッシュをロードした箇所・キャッシュ自体への影響がなくなった - イニシャライズ処理が簡潔になった(複雑なstructの場合この限りではない)
extensionをつかう
//: Playground - noun: a place where people can play import Foundation protocol HasId { var id: String { get } } protocol Mergeable { func merge(other: Self) -> Self } typealias CacheKey = String protocol KeyCreator { func key() -> CacheKey } protocol Cacheable : KeyCreator, Mergeable {} extension Cacheable where Self: HasId { func key() -> CacheKey { return id } } struct CacheStore<CacheableValue: Cacheable> { var cache = [CacheKey:CacheableValue]() mutating func save(value: CacheableValue) { if let exist = cache[value.key()] { cache[value.key()] = exist.merge(other: value) return } cache[value.key()] = value } func load(keyCreator: KeyCreator) -> CacheableValue? { return cache[keyCreator.key()] } } protocol Car: HasId { } struct FuelCar: Car { var id: String var fuelGallon: Int } extension FuelCar: Cacheable { func merge(other: FuelCar) -> FuelCar { return FuelCar(id: self.id, fuelGallon: other.fuelGallon) } } func print<Key: KeyCreator>(key: Key,store: CacheStore<FuelCar>) { print("fuelGallon: \(store.load(keyCreator: key)!.fuelGallon)") } var fuelCarCache = CacheStore<FuelCar>() var car1 = FuelCar(id: "car1", fuelGallon: 0) fuelCarCache.save(value: car1) print(key: car1, store: fuelCarCache) // print: 0 car1.fuelGallon = 10 print(key: car1, store: fuelCarCache) // print: 0 fuelCarCache.save(value: car1) car1 = fuelCarCache.load(keyCreator: car1)! print(key: car1, store: fuelCarCache) // print: 10
改善されたポイント
HasIdとCacheableを準拠すれば、基本的にkeyの作成実装が不要になったstructの本実装と、キャッシュに保存するという戦略を別のブロックで書くことでコードの見通しがよくなった。
また、今回はPlaygroundなので出来ていないが
- FuelCar.swift
- FuelCar+Cacheable.swift
のように実装毎にファイルを分けることが出来るため、FuelCar.swiftではFuelCarのドメインの処理を実装し、+Cacheable.swiftではキャッシュの上書き戦略を実装するというパターン化が可能になる
ProtocolとStructのキモ(= POPの旨み)
- Protocolは抽象化・処理(性質)の共通化を記述する。
- Protocolのextensionでデフォルトの共通処理を定義していく
- 持っているプロトコルの組み合わせを条件としてextension共通処理を実装する事ができる
- Structに複数のProtocol(性質)を持つことで使えるメソッドが増えていく
Protocolとextensionの欠点
複数のプロトコル継承とextensionの実装
//: [Previous](@previous) import Foundation protocol HasId { var id: String { get } } protocol HasCategoryId { var id: String { get } } struct Book: HasId, HasCategoryId, CustomDebugStringConvertible { var id: String } let book = Book(id: "isbn-9784798142494") if let hasId = book as? HasId { print("id: \(hasId.id)") } if let categoryId = book as? HasCategoryId { print("id: \(categoryId.id)") } extension CustomDebugStringConvertible where Self: HasId { var debugDescription: String { return "hasId: \(id)" } } extension CustomDebugStringConvertible where Self: HasCategoryId { var debugDescription: String { return "hasCategiryId: \(id)" } } // If you make comment below, you can get any compile errors. extension CustomDebugStringConvertible where Self: HasId & HasCategoryId { var debugDescription: String { return "hasId: \(id), hasCategoryId: \(id)" } } debugPrint(book)
問題点
- 変数名の重複が予期せぬところでありうる
- 変数名が重複し、型が同じだった場合にコンパイルできてしまう
- 変数名が重複し、型が違った場合はコンパイルエラーになる
where Self: HasId,where Self: HasCategoryIdのデフォルト実装をしつつ、両方のプロトコルを持つstructを定義すると、両方のプロトコルを定義したextensionも定義しなければならない(どっちの実装を使うかはコンパイラが判断できないため)
したがって、protocolの実装に気をつけなければ、バグを生む可能性やprotocolの定義の仕方によって実装方針が制限される可能性があるということも念頭に置かなくてはならない。
すべてPOPで書くことが出来るのか?
結論から言うと無理。理由はUIKitなどiOSのSDKがオブジェクト指向であるから、
その境界ではその限りではないし、structよりもclassが簡潔に書ける場面もありうる。例えばDI対象のオブジェクトとか、都度インスタンスを作りたくない場合はclassの参照を渡したほうがシンプル。
"実装できるならPOPに寄せる"という温度感で実装するのがちょうどいいように思える。
言い換えれば、「POPで実装できるか?」をOOPで実装する前に1度考えるということ。
まとめ
- Swift書くなら
protocol,extension,structorenumでProtocol Oriented Programmingを意識する - 実装するときは1度POPで実装できるか考える
引用
ImeFragmentというライブラリを公開しました!キーボード開発でもFragmentを使う!
この記事はCyberAgent Developers Advent Calendar 2016の20日目の記事です。
19日目はstrskさんでGKEのノードプールを利用したKubernetesのアップグレードでした。 ちなみにstrskさんは元々飲食業界ではたらいていてCSで入社→今はAbemaTVでGKE運用してる方です。スゴイ、、、!
明日は...○○です。
アドベントカレンダーには去年から参加し始めていて、2015年に書いた記事はこちらです。
同期系スマホアプリのリリースサイクル・テストについて - will and way
1年前はAppleのアプリレビューが1週間くらいだったのか。。。2, 3日で返ってくるようになったのは革命的な出来事だったな〜。
さて、本題のImeFragmentに入っていきましょう!
ImeFragmentというライブラリを公開しました
https://github.com/matsuokah/ImeFragmentgithub.com
一言で言うと、InputMethodServiceでもFragmentとほぼ同じように使って実装ができるというライブラリです。
とりあえず作った感じなので、整理はこれからですが。
IME開発のキモとなりそうなポイントをAndroidのAdventCalendar::day11でInputMethodService(キーボード)開発の勘所となりそうな項目という記事に書きました。
その中にServiceではFragmentは使えないという項目がありました。ImeFragmentはそれを解決しライブラリ化したものです。
Fragmentが使えると何が良いのか?
アプリを実装している感覚で部品が開発できる。アプリの実装が使いまわしやすいということです。
アプリ開発の中でFragmentというインターフェースに慣れ親しんでいます。それは、フラグメントはアプリのライフサイクルだったり、ViewPagerのように動的にアタッチ/デタッチがされた場合のハンドリングだったりします。
Fragmentのようなインターフェースを持つクラスがないので、InputMethodServiceの実装がもりもりになってしまいます いわゆる、"マッチョなActivity"のように、"マッチョなInputMethodService"が避けられない状態です。
"マッチョなInputMethodService"を分割していくということは、コントローラとなりうるクラスを作るということになります。また、そのコントローラの要件はInputMethodServiceに応じたライフサイクルを持つことや、アプリ同様にonTrimMemoryのようなアプリのライフサイクルにも対応している必要があります。
結局、Fragmentが欲しいということです。
Fragmentという粒度のクラスができることによって、Fragmentが依存したいクラス(PresenterやUseCaseなど)の単位もアプリと同じように使えますし、使うイメージも湧きやすいです。
Imeに対するImeFragmentのライフサイクルのマッピングについて
InputMethodServiceはActivityよりも幾つかのライフサイクルのステップが少ないことや、アクションバーを持たないなどの違いがありますが、基本となるonCreateからonDestroyまでのライフサイクルは同じようにマッピングすることが出来ました。
なので、実際にはActivityで使う場合と同じように使うことが出来ます。
サンプルの紹介
InputMethodServiceでViewPagerを使ってみた例です。

build.gradle
dependencies {
compile 'jp.matsuokah.imefragment:imefragment:1.0.1'
}
bintray, jcenterにホストしてあります。
SampleImeService.java
public class SampleImeService extends ImeFragmentService { @Override public View onCreateInputView() { setContentView(R.layout.ime_main); adapter = new SampleFragmentPagerAdapter(getImeFragmentManager()); WindowManager wm = (WindowManager) getSystemService(Context.WINDOW_SERVICE); DisplayMetrics dm = new DisplayMetrics(); wm.getDefaultDisplay().getMetrics(dm); int windowHeight = dm.heightPixels; View wrapper = findViewById(R.id.ime_wrapper); ViewGroup.LayoutParams params = wrapper.getLayoutParams(); params.height = (windowHeight * INPUT_VIEW_HEIGHT_PERCENTAGE) / 100; wrapper.setLayoutParams(params); ViewPager pager = (ViewPager) findViewById(R.id.pager); pager.setAdapter(adapter); return super.onCreateInputView(); } }
SamplePageFragment.java
ublic class SamplePageFragment extends ImeFragment { private static final String POSITION_KEY = "position_key"; @Nullable @Override public View onCreateView(LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) { View view = inflater.inflate(R.layout.fragment_ime_page, null); Bundle bundle = getArguments(); int position = bundle.getInt(POSITION_KEY); TextView label = (TextView)view.findViewById(R.id.position); label.setText(String.valueOf(position)); return view; } public static ImeFragment newInstance(int position) { ImeFragment fragment = new SamplePageFragment(); Bundle bundle = new Bundle(); bundle.putInt(POSITION_KEY, position); fragment.setArguments(bundle); return fragment; } }
解説
public class SampleImeService extends ImeFragmentService { @Override public View onCreateInputView() { setContentView(R.layout.ime_main); return super.onCreateInputView(); } }
onCreateはこれはお作法になります。setContentでrootとなるViewをImeFragmentServiceでinflateしています。
理由は、以下の2つです
- InputMethodServiceはonCreateInputViewの時にViewをさわる状態ができている
- Fragmentを管理する機構の中で親のビューを必要とするため
また、ImeFragmentServiceにはfindViewByIdを実装したので、ActivityのようにViewを取得できるようになっています。
Fragmentに関してはほぼ、解説する必要はないですね。元のFragmentと全く同じです。
実装内容について
本家のサポートライブラリの実装を参考にし、必要なメソッドを再実装していった形になります。Fragmentの管理に使われているクラスにはActivity/Serviceに依存しない実装のものがいくつかあったのですがパッケージプライベートな処理に手を入れる必要があり、コピーしてパッケージにいれています。サポートライブラリのクラスをそのまま使っていたりもします。インターフェースとか。
変わっている点は以下のとおりです。
- Activityにあって、Serviceにない機能の削除
- Picture in PictureやMultiWindowMode、OptionsMenuはImeでは不要。
- InputMethodServiceに合わせて、fragmentのライフサイクルのマッピングを調整
- onCreate ⇔ onCreate
- onCreateInputView ⇔ onCreateView
- onStartInput ⇔ onStart
- onWindowShown ⇔ onResume
- onFinishInput ⇔ onPause
- onWindowHidden ⇔ onStop
- onDestory ⇔ onDestroy
バグや機能追加のPRまってます!
Androidの開発を始めてから2ヶ月の人間が作ったライブラリなので、保証はできません!リファクタもまだまだ。。。 ということで、コントリビューションをお待ちしております!issueだけでもっ!
https://github.com/matsuokah/ImeFragmentgithub.com
まとめ
InputMethodServiceでもFragmentを使えるようにしました。これによってActivityを作る感覚でキーボードを開発できるようになりました!
趣味でキーボード触ってるんですが、アプリとまた違った可能性を感じています!
変換予測とか考えるのタノシイっ(๑•̀ㅂ•́)و✧
また、このライブラリを開発した副産物として、ActivityとFragmentの関係やFragmentのライフサイクルがどのようなコードなのかを知ることが出来ました。
AndroidのBaseやAndroid Support Libraryのリポジトリ、読んでみると面白いですね!
キーボードを掃除した
そういえば、今年HHKBの無印字を買ったんです。今年買ってよかったものの一つです。
そんなHHKBですがホームページに行くと以下のような文章が書いてあります。
アメリカ西部のカウボーイたちは、馬が死ぬと馬はそこに残していくが、どんなに砂漠を歩こうとも、鞍は自分で担いで往く。馬は消耗品であり、鞍は自分の体に馴染んだインタフェースだからだ。 いまやパソコンは消耗品であり、キーボードは大切な、生涯使えるインタフェースであることを忘れてはいけない。 [東京大学 和田英一 名誉教授の談話]
Happy Hacking Keyboard | 和田先生関連ページ | PFUより転載
ということで、オレたちとっての鞍を大切にあつかうべく掃除しました!
キーボードとか携帯とか常に手で触ってるものって汚いって言いますしね!
掃除風景

実は箱に入れて毎日持ち歩いています笑
少し箱の角が擦れてますね。専用のケースが有るらしいですが、この箱で十分です。
 キーボードのトップを取るにはKey Pullerを使います。
キーボードのトップを取るにはKey Pullerを使います。
クリップとかで頑張れば取れますが、傷がつくので気をつけてください...
ちなみに、WindowsPCがメインの頃、FILCOのMajestouchの茶軸を使ってたんですが、Key Pullerがキーボードについてきました。ヤサシイっ!!
 こんな感じで抜けます
こんな感じで抜けます
 キートップを横に並べてみました。
キートップを横に並べてみました。
叩きやすいように、1行ごとに角度が違っています。
ラップトップのように平面と何が変わらないんだ?と最初思ってたけど、平面のキーボードは手首の移動の距離が多く、不便に慣れてたんだな〜と感じました。(主観)
 こんな感じで全部取りました。混ざると面倒なので、行ごとに100円ショップの水切りネットに小分けします。小分けダイジ!!
こんな感じで全部取りました。混ざると面倒なので、行ごとに100円ショップの水切りネットに小分けします。小分けダイジ!!
 キートップの洗浄には重曹を使います。
キートップの洗浄には重曹を使います。
洗面台にお湯を張って、大さじ3杯ほど溶かし、かき回して30分くらい放置します。
 つけ置きが完了したら、十分に水で洗いで、外に干します。水切りネットのお陰で干すのも楽!
だいたい乾いたら最後にドライヤーで完全に乾かします。これもネットの上からでOK
つけ置きが完了したら、十分に水で洗いで、外に干します。水切りネットのお陰で干すのも楽!
だいたい乾いたら最後にドライヤーで完全に乾かします。これもネットの上からでOK
 キートップを洗浄している間に、キーボードのゴミを掃除機で吸い取ります。
キートップを洗浄している間に、キーボードのゴミを掃除機で吸い取ります。
取れない細かな汚れは、カメラを清掃する用のブラシ付きのブロアーを使いました。
 掃除に夢中になって、最後の方の写真がかなり抜けちゃってますがこんな感じで掃除が終わりました!
掃除に夢中になって、最後の方の写真がかなり抜けちゃってますがこんな感じで掃除が終わりました!
キーボードの間から見えるチリがなくなったのでかなり清潔感が出たのでは!?!?!
[asin:B000EXZ0VC:detail] HHKB最高っ!
良いルーターを使うのはもはやライフハックつだ!!! TP-LINK AC3150 レビュー
Amazon Cyber Mondayあざす!!!
買ってしまった!良いルーター!それは TP-LINK Archer 3150!
TP-LINK? 聞いたこと無い?
私自身も日本ではバッファロー、エレコム、NECが有名すぎて、TP-LINKを知らなかったんですがTP-LINKは世界シェア43%の企業。
最速のワイヤレス規格である802.11adのルータを世界初でお披露目するほどです。
ガジェット好きの先輩の家に行ったらTP-LINK Archer C9が置いてあって、繋いで見たところ接続の安定性・速度に感動したのがきっかけ。
")
そして、現在使っているBuffalo WZR-600DHPも2012年発売の機種なので古くなってきたし、TP-LINKのルータに買い換えよう!と
2週間程しらべたり、チャンスを伺っていました。
"日本で発売される最上位機種"のArcher5400が12月中に発売予定なので、こちらを買うつもりでいたが、
AmazonのCyber MondayでArcher3150がセールになっていて15,800円に値下がりしてたので買ってしまった!!!ヨドバシでは22,000円程なので、ポイントを考えても安かったです。
現在でも20,000円前後なのでAmazonで買うのがおすすめかな?ポイントが付くヨドバシでもいいかも(๑•̀ㅂ•́)و✧
上記で"日本で発売される最上位機種"と書いたのは
日本で公式に発売される予定がたっていないであろうTP-LINK AD7200がAmazonで販売されているから。
AD7200は"世界初の802.11ad対応のルータ"で、Amazonでは最安で4万円程ですが、元値は$350前後のようです。発売されてから1年たつのに割高。 Amazon, Rakuten, 公式サイトをみても品薄な感じです。 公式販売されないということは、技適が通っていないかもしれません。
Archer 3150で満足できない!というかたは素直に12月中発売のArcher 5400を待ちましょう。
話を戻しまして、、、金曜日に注文して、本日土曜日に到着したので早速開封・セットアップしレビューしていきます!
開封の儀・セットアップ
はい、箱ドーーン

でかい。開封の儀を執り行います。

同梱物は本体、アンテナ x 4, 電源コード, 電源アダプタ

ポートが
背面にはWAN x 1, LAN x 4
側面にはUSB2.0 x 1, USB3.0 x 1

Mac Book Air 11inchを横に並べると大きさがより分かる。
あとは接続設定しておしまい
PCでセットアップした場合Wi-Fiに接続しセットアップの手順に従って入力していけば3分くらいで終わりました。
上記のブログではWebのセットアップ手順が載っています。MacBookPro Touchbar 13inchとの大きさの比較も載ってます。考える事同じ笑
そもそも、MacBookAirの11inchと同じくらいの大きさってことになるMacBookProのTouchbarの13inchは相当コンパクトだな・・・!!!
が、今回はせっかくなのでアプリから設定しなおしてみる。
今回はAndroidのアプリです
1. ルーターを選択

2. 設定項目 > インターネット

3. 各欄の入力
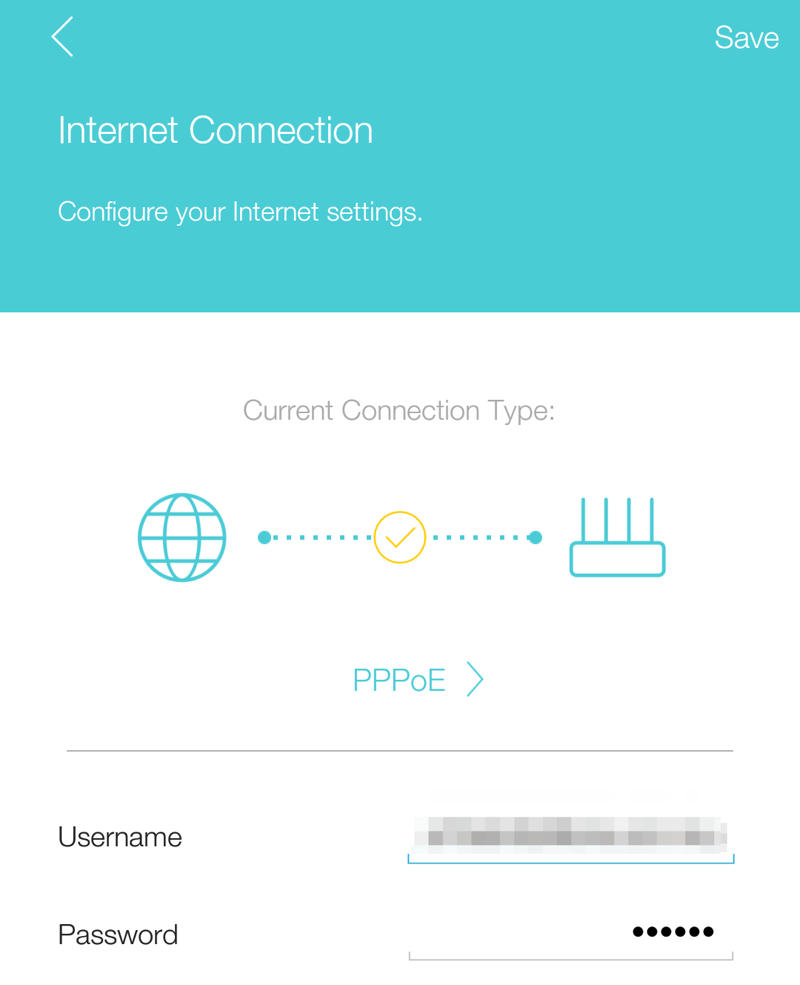
これで終わりです。
基本スペック
Archer 3150の製品情報、仕様より抜粋して転載しています。
ワイヤレス規格規格
IEEE 802.11ac/n/a 5GHz IEEE 802.11b/g/n 2.4GHz
セキュリティ
64/128-bit WEP、WPA/WPA2、WPA-PSK/WPA-PSK2 暗号化方式
特徴
1. MU-MIMO
マルチユーザー、マルチインプット、マルチアウトプットの略で
簡単にいうと、複数機種を同時接続してもサクサク!ということです。
しかし、受信側もMU-MIMOに対応していないと有効になりません。
私の普段使いであるスマホのXperiaZ5とNexus9はMIMO対応で、MU-MIMOではないようです。(製品ページのスペックを読んだり、ググったりしたが見つからなかったので。)
私が自宅で使っている2012 midのMac Book Pro Retinaは802.11acにすら対応していない。買い替えどきかな。
2. デュアルコア・コプロセッサx2搭載
ルーターでデュアルコアってきいたことなかったんですが、ハイエンドルーターでは当たり前のようです。
NAS接続したり複数の端末を同時に動画を見てもヌルサクなのはこのおかげかも?
欠点としては若干の発熱があることです。ファンはうるさくないのですが表面がほんのり温かくなります。
ネットワークテストしてみる
5GHzのネットワークに繋いでテストしてみます。
スピードテスト1 単体でテストしてみる
使用アプリ
Speed Test
使用デバイス
Nexus9(MIMO対応)
DL: 67.49Mbps
UL: 93.80Mbps
スピードテスト2 複数台で同時にテストしてみる
使用デバイス
Nexus9(左)の結果
DL: 25.91Mbps
UL: 64.04Mbps
XperiaZ5(MIMO対応)(右)
DL: 24.73Mbps
UL: 32.43Mbps
さすがにWANがボトルネックですね!各値を足すと単体でテストしたときとほぼ同じ数字になります。
スピードテスト3 Youtubeのシークを同時にしてみる
※音が出ます
使用デバイス
Nexus9(左)
XperiaZ5(右)
シークが早い気がする。多分。
RSSI値を調べる
ルーターがを置いているリビングと廊下を隔ててたところにある寝室でテストしてみました。
dB値が大きい(-なので値が低い)方が電波強度は強いです。
MBPのWi-FiをOption + Clickで調べられます。
また、このテストはルーターの置き場所や遮蔽物の有無によって結果が変わって来ることが注意点です。
5GHz

リビング: -39dBm
寝室:-65dBm
2.4GHz

リビング: -40dBm
寝室:-53dBm
ということで、2.4GHzの方がさすがに隔てた部屋でも強いですね!
前のルータだと2.4GHzのみで寝室に移動すると電波強度が80dBm程度でした。(スクショ撮り忘れた)
また主観ではありますが、接続自体も不安定だったので改善されています。寝室では、頻繁にWi-Fiの検索中になっていた。
まとめ
ということでTP-LINKのWi-FiルータArcher 3150を紹介しましたが
快適なWi-Fiはもはやライフハックなのでは?と感じる体験レポートでした。ぜひご検討あれ!
InputMethodService(キーボード)開発の勘所となりそうな項目
この記事はAndroid Advent Calendar 2016 - Qiitaの11日目の記事です。
昨日は@yuyakaidoさんのData Binding Tipsでした。 明日は@rei-mさんのDagger2とMockitoでUIテストはじめる話です。
11日目はAndroid StudioでKotlinのプロジェクトが新規で作られるソースを
そろそろKotlinを選べるになってほしいmatsuokahが担当いたします。
InputMethodServiceに触れていて、キーボードのクセを掴まねば!ということで、勘所となりそうな項目を書いてみます。
InputMethodService(以下、ほぼ同義のIME)とは
いわゆるキーボードの継承元となるServiceです。
Simeji、Google日本語入力、POBox、ATOKが日本では有名ですね。
IMEはググっても、ヒット数が少ないのでマイナーな分野ですね。
IMEアプリの作り方はハンズオン記事を見ればわかります。
サンプルもあります。
ざっくりキーボードの作り方
- InputMethodServiceを継承したクラスを作成
- Android Manifestにサービスの定義を行う
- カスタムしていく
本当にざっくりですがこんな感じです。
ハンズオン記事ではMainActivityに<category android:name="android.intent.category.LAUNCHER"/>を記載していないですが、
設定アプリとしてActivityを使うはずなので消さなくて良いでしょう。
何のメソッドをオーバーライドすべきか?
を見て、リストしてみました。
Intentionally emptyとコメントが書かれているメソッド
- onBindInput
- onUnbindInput
- onInitializeInterface
- onStartInput・・・初期化
- onStartInputView
- onStartCandidatesView
- onWindowShown
- onWindowHidden
- onDisplayCompletions
- onViewClicked
- onUpdateCursor
- onUpdateCursorAnchorInfo
デフォルトでnullを返却しているメソッド
- onCreateInputView・・・ここでビューを作成する
- onCreateCandidatesView
デフォルトでfalseを返却している
- onTrackballEvent
- onGenericMotionEvent
フルスクリーンモード
- onEvaluateFullscreenMode・・・画面を回転させた時に、フルスクリーンモードにするか否か
ということで、基本的にはここらへんのメソッドをオーバーライドしてIMEをカスタムしていくことになります。
リストにはライフサイクルに関わるメソッドも含まれています。
また、
ライフサイクル

Android Developers - creating-input-methodより転載
というような単純なライフサイクルとなっています。
しかし、思わぬ所でイベントが発火されるケースが幾つかあります。
操作して、ライフサイクルでログを追っていきましょう。

これが最もシンプルなIMEの操作だと思います。実際のログは以下のとおりです
## MyImeへ切り替えを開始 D/ImeService: onCreate D/ImeService: onCreateInputMethodInterface D/ImeService: onCreateInputMethodSessionInterface D/ImeService: onInitializeInterface D/ImeService: onBindInput D/ImeService: onStartInput, restarting : false D/ImeService: onCreateInputView D/ImeService: onCreateCandidatesView D/ImeService: onStartInputView, restarting : false D/ImeService: onWindowShown ## IMEの表示が完了 ## 別のIMEへの切り替えを開始 D/ImeService: onFinishInputView, finishingInput : true D/ImeService: onFinishInput D/ImeService: onStartInput, restarting : false D/ImeService: onStartInputView, restarting : false D/ImeService: onUnbindInput D/ImeService: onFinishInputView, finishingInput : true D/ImeService: onFinishInput D/ImeService: onDestroy
思わぬ所でイベントが発火されるケース
と、述べましたが
onStartInput, onStartInputViewが何故かonFinishXXXの後に呼ばれています。
私はStartと書いてあるのでIMEが立ち上がって入力が開始された時だけ発火すると勘違いしていました。
ではなぜ発火されているか。それは、編集していたEditTextのフォーカスが外れた時に、IMEの状態をリフレッシュするためです。
IMEは1つのインスタンスであるのに対し、画面には複数のEditTextが存在することが多いです。
編集するEditTextが切り替わると、すでに入力されているテキストや入力タイプ(Numeric, AlphaNumeric, Passwordなど)が変わります。
したがって、onStartInputでは一時的な入力データなどを破棄し、引数で与えられているEditorInfoオブジェクトの情報から次の入力に備える必要があります。
実はSDKのドキュメント冒頭にあるGenerating Textという項目で述べられています。ドキュメントはしっかり読もう。
そして、ログに出てきてないので気づきにくいのですがonWindowShownに対し、onWindowHiddenが呼ばれていません。
onWindowHiddenはIMEが破棄されないが非表示になるときかタスクマネージャ起動時に発火されます。
従ってonWindowHiddenでTearDownするのは好ましくない実装だと思います。
onStart系のライフサイクルメソッドでスクラップアンドビルドしていくのが良いかなと個人的に思います。
Fragmentが使えない
私はIMEでもFragmentが使えると思いこんでいました。
ところがFragmentはActivityに依存しているのでServiceで使えないのは当然なわけであります。
iOSのLINEのスタンプのようなUIを実装してみようと思っていたのですが、
Fragmentが使えないのでViewPagerを使うにはAdapterの独自実装が必要となります。
LINEのUIなので、画像が多い前提となるため、Fragmentのライフサイクルの様にページを破棄することも考慮に入れる必要があります。
ということで、ひとまず最低限の実装でFragment・FragmentManager・FragmentPagerAdapterの実装を真似て作ってみました。FragmentのTransactionは実装していません。

ImeFragment.kt
abstract class ImeFragment() { lateinit var service : InputMethodService val context : Context get() = service var tag : String = "" var containerId : Int = 0 var view : View? = null open fun onCreate() {} open fun onCreateView(inflater: LayoutInflater, container : ViewGroup?, savedInstanceState : Bundle?) : View? { return null } open fun onAttach() {} open fun onDetach() {} open fun onDestroyView() {} open fun onDestroy() {} }
ImeFragmentManager.kt
class ImeFragmentManager(val service : InputMethodService, val rootView : View) { val fragments : HashMap<String, ImeFragment> = HashMap() val attached : HashMap<String, ImeFragment> = HashMap() fun add(containerId : Int, imeFragment : ImeFragment, tag : String) { if (fragments.containsKey(tag)) throw IllegalArgumentException("already container has fragment") imeFragment.containerId = containerId imeFragment.tag = tag fragments[tag] = imeFragment attach(containerId, imeFragment, tag) } fun remove(tag : String) { if (attached.containsKey(tag)) { detach(attached[tag]!!) } val fragment = fragments[tag]!! fragment.onDestroy() fragments.remove(tag) } fun findFragmentByTag(tag : String) : ImeFragment? = fragments[tag] fun attach(containerId : Int, imeFragment : ImeFragment, tag : String) { if (!fragments.containsKey(tag)) throw IllegalArgumentException("fragment is not added") if (attached.containsKey(tag)) throw IllegalArgumentException("already container had attached") attached[tag] = imeFragment imeFragment.service = service val container = rootView.findViewById(containerId) as? ViewGroup imeFragment.view = imeFragment.onCreateView(LayoutInflater.from(container?.context), container, null) container?.addView(imeFragment.view) imeFragment.onAttach() } fun detach(imeFragment : ImeFragment) { if (!attached.containsValue(imeFragment)) throw IllegalArgumentException("fragment not found") val container = rootView.findViewById(imeFragment.containerId) as? ViewGroup container?.removeAllViews() imeFragment.onDestroyView() attached.remove(imeFragment.tag) imeFragment.onDetach() } }
ImeFragmentPagerAdapter.kt
abstract class ImeFragmentPagerAdapter(private val imeFragmentManager : ImeFragmentManager) : PagerAdapter() { abstract fun getItem(position : Int) : ImeFragment override fun instantiateItem(container : ViewGroup?, position : Int) : Any { container ?: throw IllegalArgumentException("") val tag = createTag(container.id, position) var fragment = imeFragmentManager.findFragmentByTag(tag) if (fragment == null) { fragment = getItem(position) imeFragmentManager.add(container.id, fragment, createTag(container.id, position)) } else { imeFragmentManager.attach(container.id, fragment, createTag(container.id, position)) } return fragment } override fun destroyItem(container : ViewGroup?, position : Int, obj : Any?) { val fragment = obj as ImeFragment imeFragmentManager.remove(fragment.tag) } override fun isViewFromObject(view : View?, obj : Any?) : Boolean = (obj as ImeFragment).view == view companion object { fun createTag(viewId : Int, itemId : Int) : String = "android:ime_switcher:$viewId:$itemId" } }
Fragmentっぽい実装を用意することで、Page単位にコントローラを分離できること・ドメインレイヤーとの繋ぎの所にもできるので欠かせないな〜という所。
ココらへん、ライブラリ化して公開します。多分。
小ネタ. Macで音のボリュームを無段階調節
知らなかったので驚いた
Shift + Option + Functionキーで音量とかディレスプレイ輝度の調整がより細かくできる!!!
普通にボリュームup/downすると以下のようにメモリ毎にボリュームが変わりますが

Shift + Optionを推しながら調節すると・・・

うおおおおおおおおおおおおおおおおお!!

うおおおおおおおおおおおおおおおおおおおおおおおおおおおおおお!!

ま、そんなに細かく調整する必要ないんですけどね
僕のPCはMBPですが壁紙はiMacの基盤です
Androidのコードを書く前にコーディングに集中できる状態を作る
はじめに
この投稿はAndroid その3 Advent Calendar 2016 - Qiitaの5日目の記事です。
4日目はkimukouさんのrealm-gradle-plugin 2.2.1 と Android Realm Browserでした。
6日目はkimukouさんの2016年末のAndroidでのSSL対応に関してです。
Androidのコードを書く前にコーディングに集中できる状態を作る
今年のAdvent CalendarはAndroidでKotlinを導入する話がかなり多くて、Kotlinが浸透しているんだな〜と感じています。
かくいう私もKotlinを使ってみた所感やテクニックのネタを考えてたんですが、Kotlinは愚かAndroidを本格的に開発し始めて2ヶ月ですので、エキスパートな部分は先人達にお願いするとします。
最近異動して、0からのプロジェクトに携わらせてもらっていて、コードを書く前に環境を整えることを最初にやりました。その時のまとめになります。
目次
- なぜやるべきか。ずばり何をするのか
- 命名規則, Code Style
- プロジェクト構成, BuildType/Product Flavor, DI
- データ層からプレゼンテーション層のサンプル実装
- CI
- プルリクのルールを作る
- 必ず使うSDK, ツールの導入
- テンプレートコード・スニペットをつくる
- 開発環境のプロビジョニングをつくる
なぜやるべきか。ずばり何をするのか
プロジェクト初期になぜやるべきか。
先に決めて開発期〜リリースの間にコーディングに集中できる環境があると、エンジニアの精神衛生が良い状態が保たれるからです。
そして、プロジェクトが発足したての頃は仕様が 無い or 部分的 or 一朝一夕で変わるが当然なので機能実装以外に時間を割く時間が作りやすいです。
ずばり何をするのか。
ルール化と自動化です。
プルリクを前提とした開発では、コードレビューのコストを大幅にされるでしょう。ルールと自動化をメンテしましょう。コードレビューで主観的(書き方の好み)な議論をするのは楽しいですが開発スピードとのトレードオフになります。世に出ていないサービスはスピードの方が重要でしょう。
では、さっそく各項目について、まとめをつらつらと書いていきます。
命名規則, Code Style
命名規則
大雑把なルールを作り、必要になったらルールを追加していきます。
接頭辞 or 接尾辞
リソースは接頭辞ベース、クラスは接尾辞ベース
Android Best Practices#Resourcesをベースにすると良い。日本語にも翻訳されています。
レイアウトの変数に名前をつける
レイアウトの変数名に概念や機能性をもたせることで、デザイナーと列挙された数値の共通認識をもつことが出来ます。 Androidはldpi(x0.75)を考慮して4の倍数でレイアウトをする必要があるので、そこだけ3dpみたいなことは極力避けたいです。
現在のプロジェクトではマージンやパディングの数値(4, 8, 16, 24)にspacing_s, spacing_m ... と名前をつけてます。
フォントのサイズにはHTMLのタグ名を参考にすると良いかもしれません。
title, header, body, paragraph ...
コンテンツの優先順位でフォントサイズを変えるということが直感的になります。
※ルール化することでデザイナーの発想の範囲を狭めることがあります。
Code Styleをととのえる
スペースや改行は好みが分かれるので、先にルールを決めるのがいいです。
Code StyleはAndroid界隈の神らしい、Jakeが在籍するSquareのコードフォーマットを拝借しましょう。
フォークして微調整してプロジェクトのルールとするのが手っ取り早いです。Google Java Style Guideをベースにチューニングします
プロジェクト構成, BuildType/BuildVariants, DI
プロジェクト構成をつくる
いわゆるアーキテクチャです。MVP/MVVM/MVCなどのパターンから、どれで実装していくかを決める必要があります。
BuildType/Product Flavorを追加する
ビルドタイプを分ける(Debug, Release)
- ロギングの切り替え(コンソールログ/クラッシュログをサーバーに転送する)など
環境を分ける(development, staging, production)
- Endpointの切り替え
- アプリアイコンなどのリソースを環境毎に変える
- KeyStoreの切り替えをtaskに含める
DIを導入する
上記のアーキテクチャとビルドタイプを統合した構成を考える必要があります。 勘所はAPIのエンドポイントやログ、モックデータを返却するAPIなどを切り替えられるように意識しましょう。
例えば、Retrofitを使っているプロジェクトでdebug/release毎にRetrofitのインタセプタのDIの戦略を変えるというような事です。 debug時だけloggerのインタセプタのDIを有効にしてAPIアクセス時のに詳細なロギングをするといったことが可能です。
現プロジェクトではDIにDagger2を使っており、インスタンス戦略は
- Context(Application)スコープ
- View(Activity/Fragment)スコープ
の2つに着地しています。Contextレベルなのはドメインレイヤーから下です。
データ層からプレゼンテーション層までの一気通貫サンプルを実装する
プロジェクト構成が出来たら、その構成が本当に使いやすいか検証する必要があります。自分で実装してみるのが一番です
サンプル実装でマニュアルも同時に終わらせることが出来ますし。そして、Android初心者な私にとって一気通貫させるのは実装イメージを沸きたてるにはベストでした。
CIを導入する
とりあえずFastlaneを導入してFastfileで各環境のビルドをできるようにしておくことが重要。
Gemfileも定義して、bundle exec fastlane [ENV] type:Debugくらいのコマンドでビルドできるようにしておけば、Circle CIを導入してもdeploymentディレクティブでの細かな設定が不要になります。
実際に運用しているのは
- Circle CIでbundlerをつかってfastlaneをフック
- ターゲットとなる環境のアプリをビルド
- Crashlytics Betaにアプリをポストし、テスターグループにアプリを公開
- Slackにビルド完了通知
Fastfileにはフローを定義し、Contextにプロジェクト情報を埋め込む形に着地しています。
※FastfileはBuildType, BuildVariants, Keystoreの設定と合わせる必要があります。
プルリクエストルールを作る
前のプロジェクトのチームのプルリクにはルールが定められていて、1年以上つづけていて、とてもよかったたので概要を紹介。
- プルリクのフォーマット化
- 概要、バグフィクスの原因など
- 目的やアクションを記載する(仕様を含む、編集の意図をソースコードから汲み取らない)
- 修正の影響範囲がわかるURLを含める(開発ロードマップやCSのバグチケ)
- UI変更はBefore/Afterのスクショ必須
- インタラクションならGIFアニメ必須
詳細は割愛します。Cookpadさんの開発速度を上げるための Pull-Request のつくり方に近いです。
必ず使うSDK, ツールの導入やリスト作成する
仕様にかかわらず必要となる機能やツールは少なくとも決まってるので時間があるときに導入だけしておくことで、終盤で導入して急遽Multi Dex対応が必要になるみたいな事が減らせると思います。
- 認証(Firebaseなど)
- ログ/解析(Timber, Crashlytics, Google Analytics)
- デバッグ(Stetho, Crashlytics, leakcanary, Pidcat)
- 時間(Three-Ten)
- 暗号化(conceal)
- βテスト(Crashlytics)
- ORM(ormaなど)
- Parcelable Generatorなどのプラグイン導入
テンプレートコード・スニペットをつくる
Dagger2を使う場合にはComponent, Module, Scopeを大量生産するでしょう。
IntelliJにはファイルテンプレート機能があり、予めApache Velocityのフォーマットに従った形式でソースコードを書いておけば、ファイルの新規作成時に選ぶことが出来ます。
テンプレート化によって、フレームワークを使うときのフットワークを軽くすることが出来ます。
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME}
#end
#parse("File Header.java")
import javax.inject.Scope
import kotlin.annotation.AnnotationRetention.RUNTIME
@Scope
@Retention(RetentionPolicy.RUNTIME)
annotation class ${NAME}
開発環境のプロビジョニングをつくる
AnsibleでAndroid SDKのインストールを図る。
Android Studioがよしなにやってくれることも多いので、ツール群の導入くらい。
まとめ
プロジェクトを始める発射台となるような手順をまとめた。とにかく最初は開発しやすいように、大雑把なルールや開発を加速させる周辺を整える事が重要。
そして、ユニットテストやUIテストの導入がまだできてないので、これからやりたい。